
Castro Galante - Analítica Universitaria
Observatorio de inserción laboral universitaria en Argentina que permite explorar empleo formal, salarios y oportunidades por disciplina, región, género y gestión institucional. Incluye dashboard con filtros combinables, rankings, comparador de disciplinas y evolución temporal de los indicadores. Desarrollado como trabajo práctico final de Python para la UTN.
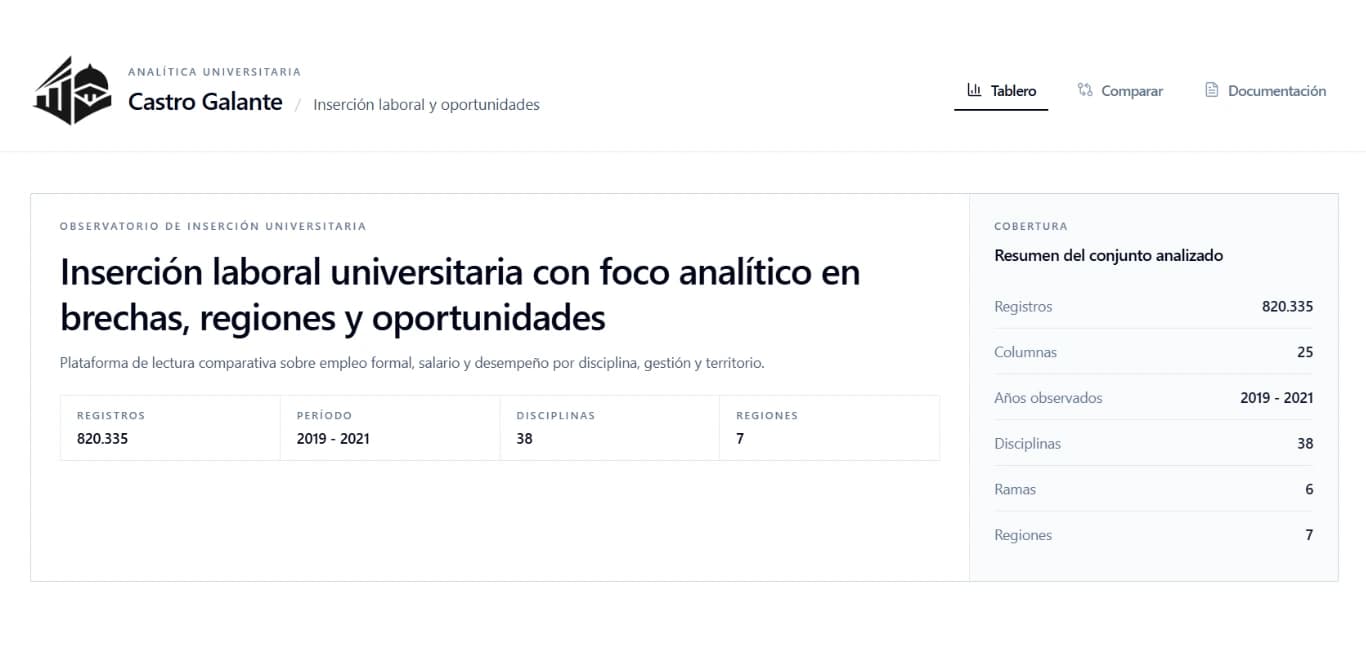
Los datos sobre inserción laboral de graduados universitarios en Argentina existen pero están fragmentados, son poco accesibles y no están pensados para ser explorados interactivamente. Un estudiante, docente o investigador que quiera entender qué pasa con el empleo formal de egresados de su disciplina, región o tipo de institución no tiene una herramienta directa para hacerlo. El trabajo práctico final de Python de la UTN fue la oportunidad para convertir ese problema en un producto real.
Una plataforma full stack que transforma un dataset CSV de registros individuales enriquecido con un diccionario Excel en un dashboard interactivo con filtros combinables por año, gestión, género, región, disciplina y rama. El backend en FastAPI con Pandas calcula KPIs, series temporales, rankings y comparativas en tiempo real. El frontend en React con Recharts visualiza todos los indicadores respondiendo a los filtros de forma dinámica. Un índice de oportunidad compuesto combina empleo formal (55%) y salario mediano (45%) normalizado para rankear disciplinas de forma comparativa.
- 01
Optimizar la carga y procesamiento de un dataset CSV grande con Pandas para que los endpoints de la API respondan en tiempo real sin recargar los datos en cada request, usando una estrategia de carga única al inicio del servidor con Lifespan de FastAPI
- 02
Diseñar un índice de oportunidad compuesto que sea comparable entre disciplinas dentro del subconjunto filtrado, normalizando ambas dimensiones sobre el subconjunto activo en lugar de sobre el dataset completo
- 03
Implementar filtros combinables en el backend que acepten múltiples valores por dimensión y los apliquen secuencialmente sin duplicar lógica entre los diferentes endpoints del dashboard
- 04
Construir el comparador de disciplinas con evolución temporal paralela usando Recharts, sincronizando dos series de datos independientes en el mismo eje temporal con escalas que preserven la legibilidad
- 01
Partir de un análisis en notebook es un punto de partida válido para un producto real: la transición de exploración a API requiere pensar en separación de responsabilidades, no solo en trasladar código
- 02
Pandas en producción requiere decisiones de memoria explícitas: dtype mappings, usecols, category dtype para columnas categóricas, y carga única con Lifespan marcan la diferencia entre una API lenta y una que responde en milisegundos
- 03
Un índice compuesto normalizado sobre el subconjunto filtrado produce rankings más útiles que uno calculado sobre el dataset completo, porque refleja el contexto real de la consulta del usuario
- 04
FastAPI con documentación automática Swagger es una ventaja real para proyectos académicos: el endpoint /docs sirve como documentación viva que cualquier evaluador puede explorar sin configuración adicional